
A brief comparson of Hicks Law, Card Sorting and SNIF-ACT
Posted by mschmettow on 15. February 2010
Modern cognitive psychology has a strong focus on information processing capabilities. This was to some extent inspired by the mathematical information theory. One of the earliest works in this spirit is Hick’s law which predicts the time T one needs to decide for one out of n equally likely options.

We may use this to predict the time a user needs to make a choice at each level of a hierarchically organized website. First, lets assume there be only one level with 5 choices. The factor c is a constant for processing speed, for the following examples we take this to be 1.

Given that A is the correct choice, the time for decision is
In the second example, there are two levels of navigation, which are not equally balanced (one subtree has 3 entries, the second has 2).
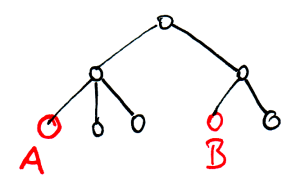
In order to reach A, two decisions have to be made and the decision time is
For reaching B the total decision time is
Thus, we can already make two observations on this small example:
- Comparing the effort of reaching A in both examples, flat hierarchies (i.e. fewer levels of the hierarchy) are preferable.
- Comparing the effort to reach A vs B in the second example, fewer entries in a navigation level make a faster decision, meaning less effort.
Decision time is effort and remember that in the card sorting method the distance measure between two topics can be defined as effort – the length of the path between either two topics. In the example below the distance between A and D is 5. But, according to Hicks law, effort for reaching A and D is not the same. Instead we get:
T(D) = log2(4)+log2(5) = 4.32
However, in total it does not make a difference whether a user wants to reach A but mistakenly arrives at D, or the other way round. He or she has to take both paths anyways.

The third tool in our inventory for analyzing navigation structures is the SNIF-ACT model that is based on latent semantic analysis (LSA) and information scent theory. This model differs from Hick’s law in that it does not take the options to be of equal probability. Instead it predicts the salience of a term based on the semantic distance to the users goal.
An interesting obervation is that all three models are based on different measures:
- Hicks law: number of choices
- Card Sorting: length of path
- SNIF-ACT: semantic distance
But, as far as I see, they would all favor flat hierarchies, which is in contrast to the common practice in web design.
To wrap it up, there are two interesting research questions:
- By combining the three approaches, can we increase the predictive power of how users travel the web and better advice of what makes an optimal design? For example, should we account for the number of choicesin the distance matrix of a card sorting study?
- Is a flat hierarchy (e.g. a site map) truly superior. Most radically this means to abandon any hierarchical structures and present a list of all topics to the user. Intuitively this does not make sense, but why?
Anybody?!


tricky said
the first two theories assume that humans are information processing ‘machines’, thus intuition is not taken into account (which maybe of influence). well, the snif-act goes somewhat more in this way, but it also states a systematic way of choosing etc, thus no influence of stress, distraction etc. I, myself, do the least things systematically… so these theories would not predict my behaviour very well…
mschmettow said
I was hesitating a little, but I think that this topic requires some more general arguments:
1) Information processing is since decades the major paradigm in psychology. In particular it has replaced two other (in my opinion clearly inferior) paradigms: A mechanistical (behaviourism) and an energetic (Freudian psychology). It may not be the be-all and end-all, but at the moment there’s no way around.
2) Most psychological theories try to find some kind of signal in the variety of human behaviour (the noise). Predictions are almost always stochastic by nature, thus only make sense for large numbers. But, exactly this is the case for websites: They are designed for a large number of people, so we can only try to judge the general tendency. There’s no way to design for each individual person.
3) Introspection is, for good reasons, abandoned in scientific psychology.
4) If people wouldn’t behave in a somewhat systematical way, there was no predictable behaviour, thus no theory, no science. Many psychological theories deal with what one would call intuition, and so does SNIF-ACT.
Ivor said
About remark 3): Could you specify what you would consider as ‘scientific psychology’? Because I my opinion, scientific psychology is psychology doing research which explains phenomenon in people. This is done with experiments. But to be able to explain and predict behavior, you’ll need concepts like fun, usability, satisfaction and many others. These concepts only contain meaning because of introspective measures (for example, you can’t measure the concept usability with reaction times alone). I do agree that introspection is inferior too a lot of measurements, but it’s still the only way to know what people are thinking. And of course, as you mentioned in remark 2), predications are made for groups, and the predictions are based on group-experiments. And a group-introspection is something that can be used, even in scientific psychology (for validating constructs for example, which apparently should be done more often according to Hornbaek (2004)).
mschmettow said
Introspection in the sense of: I validate or falsify a theory based on what I observe in my inner self. This was in reply to Tricky saying “I, myself, do the least things systematically… so these theories would not predict my behaviour very well”. I was not argueing against subjective self reports.
Ivor said
Ah okay, my mistake. But I agree, that kind of introspection isn’t very scientific. Although it is a good starting point for research. If someone thinks his/her behavior can’t be predicted, the theory/model might need an expansion so it can predict more behavior, which could possibly lead to scientific research. If the person is motivated enough and wants to go through the drag of publishing papers 😛
Ivor said
I agree with Tricky. The theory of Hick’s law is a mathematical theory and assumes people have the same reaction times on everything (and also consequently). This of course isn’t possible and far from the reality (natural world). Another problem with Hick’s law is the fact that you have to known where the element that you’re looking for is located, since a search down one path and than the other takes a lot longer than running down the right path in one go. That’s where categorisation comes in.
You should take into account that people have had learning experience with websites and thus have a mental model of how a website should work. This can be found in the card sorting task in which people will automatically divide options into groups. People have a tendency to categorize things (which would be logical because of evolution: it’s very handy to see if the object coming at you is a predator or your child). So Hick’s law is nice in theory (and may give a crude impression on the times it takes people to get to a certain option), but don’t really apply to people.
Because of this tendency for people to categorize, you would want your site to have categories (because of evolution, but which are also stated in the design patterns). This is where SNIF-ACT CAN come in. A problem with the SNIF-ACT is what was already mentioned in class: synonyms. Synonyms are not always used in a text. If you have a text about dogs, which only uses the word ‘dog(s)’, and you have another text only using ‘canine(s)’, you don’t put those two together because of the different texts. This makes it possible that a semantic distance is rated as low, although it could be quite high because of the synonyms.
Another problem with looking at text, is that texts can be biased, in that they could discuss a subject in such a way that subjects are combined, which wouldn’t be ‘normal’. If you would have text about George W. Bush, written by a republican, the semantic distance between ‘good’ and ‘bush’ will be small, although you might not think so.
These problems (and others: semantic distance in a text is not the same as in the sentence; the latter would be stronger) makes the SNIF-ACT a nice evaluation in general, but could make a few mistakes.
The best method in my eyes, is to use the card-sorting method. You make something for users, based on those users. Of course you’re going to have problems (people not being able to categorize), but it’s probably one of the most resourceful methods. It does take a lot of time, but it’s worth the effort. If you’ve already read the article about usability: you design for the user, so use the user to design!
So why wouldn’t a complete list work: people categorize, which makes information easier for them to handle.
And would a combination of the theories work? Probably would, if you take into account that both Hick’s law and the SNIF-ACT are somewhat limited into their capability of predicting human behavior. So I would recommend using these methods as extra to the card-sorting. If you don’t have the time/money to do card-sorting, than the other techniques are good ways of still getting a useful set-up of your site.
mschmettow said
I haven’t tried it but I think LSA should handle synonyms quite well. Remind that terms are located in a multidimensional Euclidian space. Hence, transitivity holds, like in general:
A is very close to B
A is close to C
—————
B is close to C
For example:
“Dog” is very close to “canine”
“Dog” is close to “hunting”
——————————-
“Canine” is close to “hunting”
Of course, we wouldn’t use the term “canine” for a municipal website, because it is very unfamiliar to the average user. But, LSA also accounts for different populations. There exist several databases for different levels of proficiency. Thus, it allows to also judge the familiarity of a word. Choosing a database for, let’s say for persons of average proficiency, the model would not propose the word “canine”, but “hond” or “huisdieren” for the page on “honden bestuur” on a municipal website.
tricky said
till now we also just talked about efficiency and ease of information finding. the above discussed theories are very well applicable for that i think. but spending times on web-sites includes also a fun-factor for most people (who do not have to search through the www for work). even if we are often not conscious of it. well, that could be one advantage as well for hierarchical sorting of topics. 🙂
another think i could think of is that as a web-administrator it is in your interest to keep users on your website as long as possible. because of the ads ($$$). but also to let them form or strengthen the image of your name. when i think of big names like mercedes or puma or so, they all spend a lot for things like corporate design, pr etc. a website is a presentation and you want to convey certain values to the users (ads about yourself?).
and of course the the third and maybe least spectacular reason could be consistency. if you are used to something is sometimes better to just stick with it (if you dont want to confuse user and make them not like you) 🙂
mschmettow said
Indeed, the concept of fun has recently gained a lot of attention in HCI. This is why a full (upcoming) lecture is dedicated to engagement and change. Especially, the concept of FLOW (from psychology of motivation) is in my opinion appropriate for situations where users really engage, instead of solely getting their tasks done.
Ivor said
The last point Tricky made is very good. In user design, consistency is a very important feature. It makes the interface for your user easier and thus more likeable.
But the other two points are not really reasons why you would use a different structure. Of course they are arguments for not going for the sitemap. So they are only reasons to use a different structure, but that won’t necessarily give you a good(=usable) structure right? So you will still need the described methods for that.
Oliver said
Hick’s law already explains why sitemapes ideally are not superior to hierarchical listings. As Ivor mentioned earlier, people tend to categorize. In my opinion, this does not answer the question but poses another one, namely why they tend to categorize.
In Hick’s law, the time decision making takes depends on the number of choices to consider. This number of choices that have to be considered is simply reduced by categorizing (see tree diagram). Therefore I conclude that either I misunderstand as well the theories as the question or Mschmettow’s assumption that Hick’s law favors flat hierarchies is wrong.
On the other hand, a use of bad labels for categories can delay the decision making process as it forces the decision maker to literally browse through all categories in order to find his preferred choice.
mschmettow said
From an applied perspective I’d say: How they categorize is the question. For a human being, what is the most comprehensible and efficient taxonomy, in particular the optimal balance of breadth vs depth.
From Hick’s law it indeed follows that one complex decision is more efficient than breaking it down into several simpler decisions. Consider a total number of 9 options. As one decision 1 out of 9 we get:
T1 = log2(10)
Breaking it down into equally balanced tree (3×3) gives:
T2 = log2(4)+log2(4) = log2(16)
T2 > T1, thus we should prefer the flat complex decision – the sitemap preferred to a hierarchical structure.
What is not considered in Hick’s law is that the user has to read and comprehend 9 terms in the flat version, but only 6 in the tree version. This gives an advantage for the tree structure. So, we may find an optimal solution balancing decision time and reading time.
Another argument for flat structures has to do with the distance matrix. When the user follows a wrong path (remember the parking license example) the costs for going back to the top level are higher the deeper the structure is.
It’s a pretty wicked problem, isn’t it?
Oliver said
I agree, now I see where my calculations have gone wrong.
How To Improve Usability With Fitts’ and Hick’s Laws | Van SEO Design said
[…] we won’t concern ourselves with details, except to say that the time it takes to make a decision (T) is dependent on the number of choices (n) and that once again this relationship is logarithmic. […]